
Meta「轻量级」KernelLLM颠覆GPU内核生成,8B参数碾压GPT-4o
Meta「轻量级」KernelLLM颠覆GPU内核生成,8B参数碾压GPT-4oMeta推出KernelLLM,这个基于Llama 3.1微调的8B模型,竟能将PyTorch代码自动转换为高效Triton GPU内核。实测数据显示,它的单次推理性能超越GPT-4o和DeepSeek V3,多次生成时得分飙升。
来自主题: AI技术研报
8321 点击 2025-05-27 18:00
 搜索
搜索
Meta推出KernelLLM,这个基于Llama 3.1微调的8B模型,竟能将PyTorch代码自动转换为高效Triton GPU内核。实测数据显示,它的单次推理性能超越GPT-4o和DeepSeek V3,多次生成时得分飙升。

英伟达,亲手打破了自己的天花板!刚刚,Blackwell单用户每秒突破了1000个token,在Llama 4 Maverick模型上,再次创下了AI推理的世界纪录。在官博中,团队放出了不少绝密武器。

2万亿Llama4巨兽一再推迟,又传出了80%团队辞职的惊人消息!目前,发言人已辟谣消息不准确,Meta或许迎来了至暗时刻。

Meta首届LlamaCon开发者大会开幕,扎克伯格在期间接受采访,回应大模型相关的一切。包括Llama4在大模型竞技场表现不佳的问题:
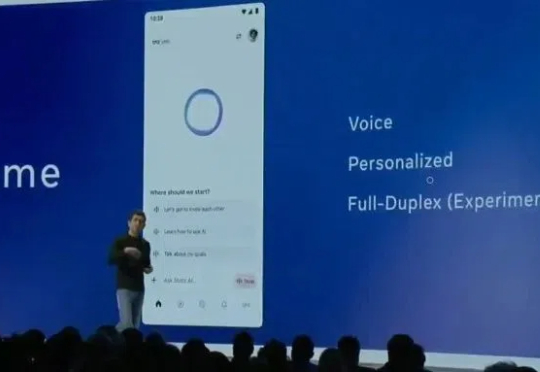
今天,在首届LlamaCon开发者大会上,Meta正式发布了对标ChatGPT的智能助手Meta AI App,并宣布面向开发者提供官方Llama API服务的预览版本。Meta AI App是一款智能助手,基于Llama模型打造,可通过社交媒体账号了解用户偏好、记住上下文。与ChatGPT一样,Meta AI App支持语音和文本交互,并额外支持了全双工语音交互(Full-duplex,

Llama 4 或许只是冰山一角。

据知情人士透露,过去一年中,Meta Platforms 曾请求微软、亚马逊等公司协助承担其旗舰大语言模型 Llama 的训练成本。该想法反映出对 AI 开发成本激增日益加剧的担忧,企业对资助开源软件犹豫不决。

悬疑小说的最后一页,隐藏着罪犯的真相。《逆转裁判》的法庭上,真凶在谎言中露出破绽。UCSD研究团队以这款经典游戏为舞台,o1、Gemini 2.5 Pro等模型化身「侦探」,测试AI的推理极限。
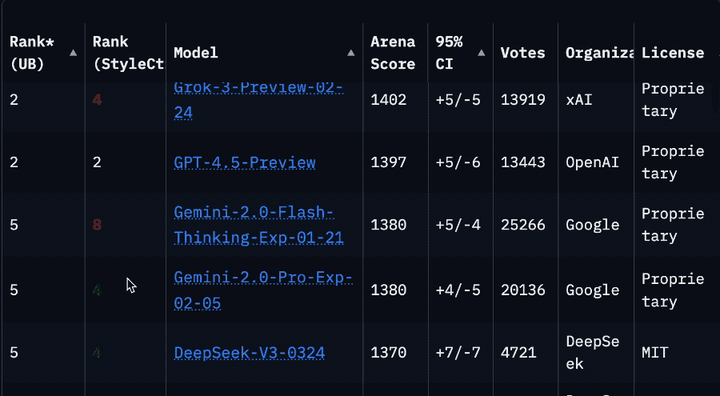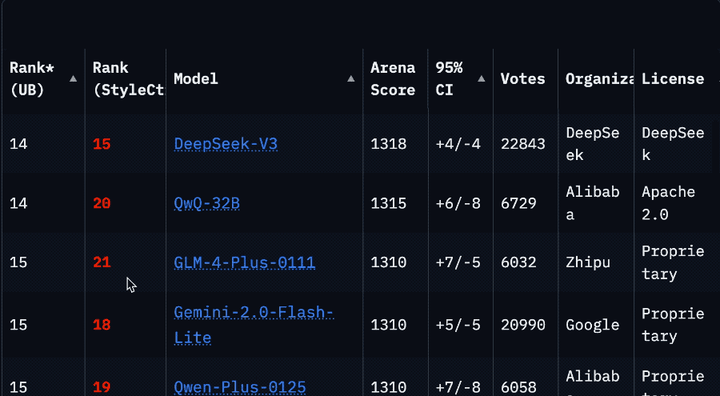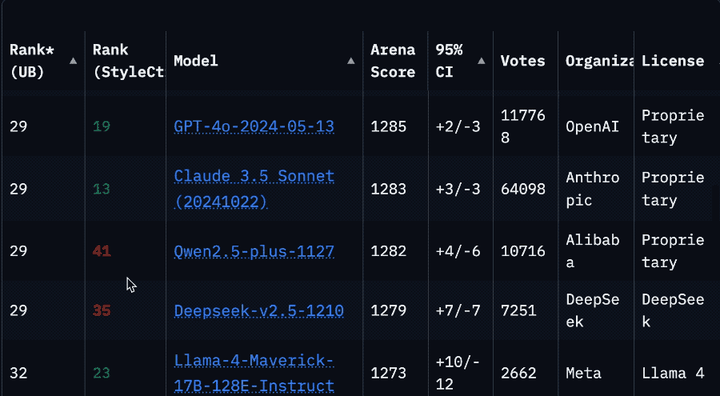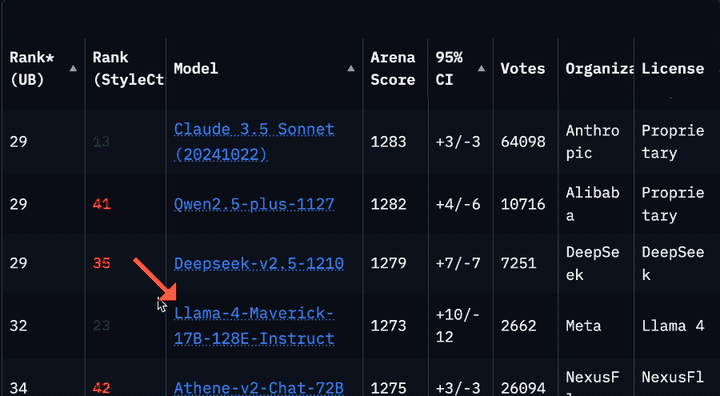
Llama 4被曝在大模型竞技场作弊后,重新上架了非特供版模型。但是你很可能没发现它。因为排名一下子从第2掉到了第32,要往下翻好久才能看到。
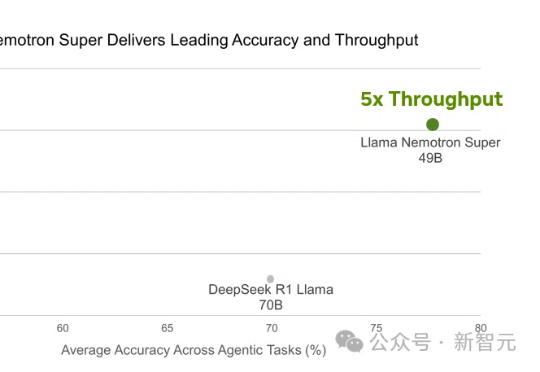
Llama 4刚出世就被碾压!英伟达强势开源Llama Nemotron-253B推理模型,在数学编码、科学问答中准确率登顶,甚至以一半参数媲美DeepSeek R1,吞吐量暴涨4倍。关键秘诀,就在于团队采用的测试时Scaling。